https://github.com/deepspeedai/DeepSpeed
GitHub - deepspeedai/DeepSpeed: DeepSpeed is a deep learning optimization library that makes distributed training and inference
DeepSpeed is a deep learning optimization library that makes distributed training and inference easy, efficient, and effective. - deepspeedai/DeepSpeed
github.com
DeepSpeed GitHub 공해보려고 합니다!

우선 처음으로 배지(Badge)라고 불리는 상태 아이콘입니다.
오픈소스 프로젝트 문서 상단에 붙는 배지(Badge) 로, 라이선스·버전·다운로드 수·빌드·보안 상태·소셜 링크 등을 한눈에 보여줍니다
- license apache2.0
→ 이 프로젝트가 Apache 2.0 라이선스 하에 배포되고 있음을 나타냅니다. - pypi package 0.17.1
→ PyPI(파이썬 패키지 인덱스)에 등록된 패키지의 최신 버전이 0.17.1임을 알려줍니다. - downloads 18M
→ 해당 PyPI 패키지가 지금까지 약 1,800만 번 다운로드되었다는 통계입니다. - build check-status
→ CI(지속적 통합) 도구에서 현재 빌드가 성공적인지(Passing) 또는 문제가 있는지를 실시간으로 보여줍니다. - openssf best practices passing
→ OpenSSF(Open Source Security Foundation)에서 권장하는 보안 모범 사례 검사 결과가 “통과” 상태임을 의미합니다. - Follow @DeepSpeedAI
→ 트위터 공식 계정 팔로우 버튼 역할을 합니다. - 日本語Twitter @DeepSpeedAI JP, 知乎, 微软DeepSpeed
→ 일본어 트위터, 중국판 지식 공유 사이트 ‘知乎(知乎)’, 그리고 Microsoft China 블로그 등 프로젝트 관련 다른 소셜·커뮤니티 채널로 연결되는 링크 배지들입니다.
Arctic Long Sequence Training(ALST) : 수백만 토큰도 한번에 학습 시키기 (좋은 이유)
실제 AI 적용 과제(문서 분석·긴 채팅·RAG 파이프라인 등)는 수십만~수백만 토큰의 긴 문맥을 다룰 수 있어야 한다.
하지만 대부분의 언어모델은 수천 토큰 내외의 짧은 시퀀스로만 학습되어, 장편 스토리 전개나 긴 추론에서는 한계가 있기 때문에
Llama 3.x·Qwen 2.5(32B) 등은 이론상 128K 토큰, Llama 변형은 최대 10M 토큰을 지원하나, 이를 실제로 미세조정(fine-tuning)하기엔 GPU 메모리와 파이프라인 제약이 커 대부분 GPU를 사용할 엄두를 내지 못한다.

단 4개의 H100 노드를 활용해도 싱글 GPU(32K) 대비 최대 시퀀스 길이를 469배(15M)로 확장할 수 있다는 걸 표로 보여줍니다.
- 시퀀스 병렬 처리
긴 토큰 열을 여러 GPU에 나눠 계산함으로써, 단일 GPU의 메모리 한계를 넘어 수백만 토큰도 한 번에 처리할 수 있습니다. - 시퀀스 타일링
입력 시퀀스를 작은 타일(tile) 단위로 쪼개 활성화(activation) 메모리 사용을 분산·축소해, 메모리 사용량을 획기적으로 줄입니다. - PyTorch 메모리 최적화
런타임 중에 숨겨진 여유 공간(free memory)을 찾아내고 재활용하여, 불필요한 메모리 오버헤드를 최소화합니다.
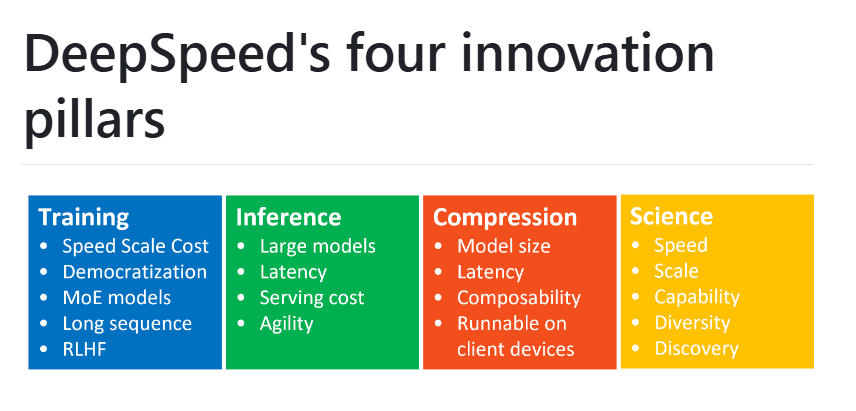
DeepSpeed의 4대 혁신 축
- Training (학습)
- Speed·Scale·Cost: 초고속·초대규모 학습을 저비용으로 달성
- Democratization: 대규모 모델 훈련의 문턱을 낮춰 누구나 활용 가능
- MoE models: MoE(전문가 혼합) 아키텍처 지원
- Long sequence: 수백만 토큰에 달하는 긴 시퀀스 학습
- RLHF: 강화학습 기반 인간 피드백(RLHF) 워크플로우
- Inference (추론)
- Large models: 수십억~조 단위 파라미터 모델 추론
- Latency: 극저지연 추론 실현
- Serving cost: 추론 비용 최적화
- Agility: 경량·모듈식 설계로 빠른 배포
- Compression (압축)
- Model size: 모델 크기 획기적 축소
- Latency: 압축된 모델의 빠른 추론 성능
- Composability: 다양한 압축 기법 조합 가능
- Runnable on client devices: 클라이언트 디바이스에서도 구동
- Science (연구·발견)
- Speed: 연구용 실험 간 빠른 반복 속도
- Scale: 대규모 실험 환경 지원
- Capability: 새로운 AI 능력 탐색
- Diversity: 다양한 모델·알고리즘 실험
- Discovery: 새로운 아이디어·기술 발굴

- Megatron-Turing NLG (530B)
- Jurassic-1 (178B)
- BLOOM (176B)
- GLM (130B)
- xTrimoPGLM (100B)
- YaLM (100B)
- GPT-NeoX (20B)
- AlexaTM (20B)
- Turing NLG (17B)
- METRO-LM (5.4B)
위에 모델들이 DeepSpeed를 통해 학습이 성공적으로 되었다는 것을 나타내고 있습니다.
물론 위에 모델 외에도 다른 모델도 사용할 수 있습니다!
HuggingFace DeepSpeed
https://huggingface.co/docs/transformers/deepspeed
DeepSpeed
DeepSpeed is designed to optimize distributed training for large models with data, model, pipeline, and even a combination of all three parallelism strategies to provide better memory efficiency and faster training speeds. This is achieved with the Zero Re
huggingface.co
허깅페이스에서 DeepSpeed 모델을 확인 할 수 있습니다.
PyPI (Python Package Index) 파이썬 패키지 설치
pip install deepspeed
위에 코드로 파이썬 패키지를 설치할 수 있습니다.
ds_report
# 출력 예시
DeepSpeed info:
version: 0.13.1 # 설치된 DeepSpeed 버전
AIO not available # AIO(Async I/O 비동기 입출력) 기능이 현재 지원되지 않음
fused_kernels: [✓] installed # DeepSpeed에서 사용하는 고성능 커스텀 연산자가 정상적으로 설치됨 의미
CPU cores: 16 # 현재 CPU 코어 수
GPU: NVIDIA A100 (CUDA 12.1) # 사용중인 GPU 모델과 CUDA 버전ds_report란?
- DeepSpeed에서 제공하는 환경 진단 도구
- 현재 시스템에서 DeepSpeed가 정상적으로 설치되었는지, 필요한 **컴포넌트(확장 연산자 등)**가 잘 작동하는지를 요약 보고서 형태로 출력합니다.
'LLM 개인 공부 > 파인튜닝 - DeepSpeed' 카테고리의 다른 글
| [LLM,DeepSpeed] LLM 모듈 파인튜닝 (6) | 2025.08.14 |
|---|---|
| deepSpeed 모델 사용 방법 및 오류 (4) | 2025.07.12 |